There are no naturally occurring negative numbers (hence why non-negative numbers are also known as ‘natural numbers’). Negative numbers only appear because of artificially signed numbers or, more commonly, they arise as a result of subtracting a larger number from a smaller number. This also means that in (–∞,+∞) variables, the value of zero typically serves an important interpretative role, e.g. the zero change in price indicates stagnated prices, zero earnings indicates break-even between income and expenses, zero degrees Celcius represents the freezing point of water.
Modulus transformations
John and Draper (1980) adjust the Box-Cox family of transformations, discussed in Transformations for [0,+∞) variables, to variables that may take values on both sides of the real line. They label their model as the ‘modulus family of transformations’, which can be applied to (|y|+1)>0 where |y| is the absolute value of y:

The sign{y} function takes the values of -1, 0, 1 according to the sign of y. This is a simple modification of the Box-Cox family and can be easily applied using Excel’s Goal Seek or Stata’s optimize command for setting the objective function of skewness equal to 0 by changing the power λ and perhaps also the constant c.
Yeo and Johnson (2000) propose a modification to the John and Draper (1980) model, as follows:

The modulus transformations by John and Draper (1980) and Yeo and Johnson (2000) map a power or log transformation on both sides of zero, whilst preserving zero. This gives rise to a reasonably good transformation for the purpose of data visualisation and univariate interpretation but it less not useful for analysis because the transformed distribution is bimodal.
Trigonometric functions
Another approach to transforming (–∞,+∞) variables is via trigonometric functions, the most popular being the inverse hyperbolic sine that maps onto the range [-709.77,709.77], and the inverse tangent which transforms the variable to the range [-π/2,π/2]. A notable application of the inverse hyperbolic sine is in the Johhson (1949) SU class of distributions (the subscript U stands for unbounded on both ends). Some like to describe the inverse tangent as the log-transformation for negative values because of similar effect.
Transforming the source variables
Many variables taking negative numbers arise as a result of subtracting a larger number from a smaller number. For example, the difference between assets and liabilities may result in negative equity, the difference between prices may be a negative spread, even inflation rates can be negative because they are calculated as the change between two positively distributed price indices. This is important information when considering transformations.
Consider net profit as the difference between revenue and expenses. Typically, we have data on net income and sales revenue, and can calculate expenses as being equal to Expenses = |Profit – Revenue|. Thus, instead of transforming a (-∞,+∞) variable we can transform two [0,+∞] variables. Theory and experience working with such data suggests that Sales and Expenses follow a lognormal distribution and taking the log transformation will turn these variables into Normally distributed, thus we can write:
The constants c1 and c2 can be exploited to shift the distribution prior taking the log-transformation to achieve higher degree of symmetry. This ratio can be interpreted as the percentage rate of revenue relative to expenses. One could also apply the Box-Cox family of transformation to the source variables, as follows:
Application
Transforming (–∞,+∞) variables can be tricky and is never straightforward. With such variables you first need to learn as much as you can about the source of negative and positive values. As an example, consider the variable Profit from Tableau’s superstore dataset. Before all, we have a look at the distributional form of Profit:
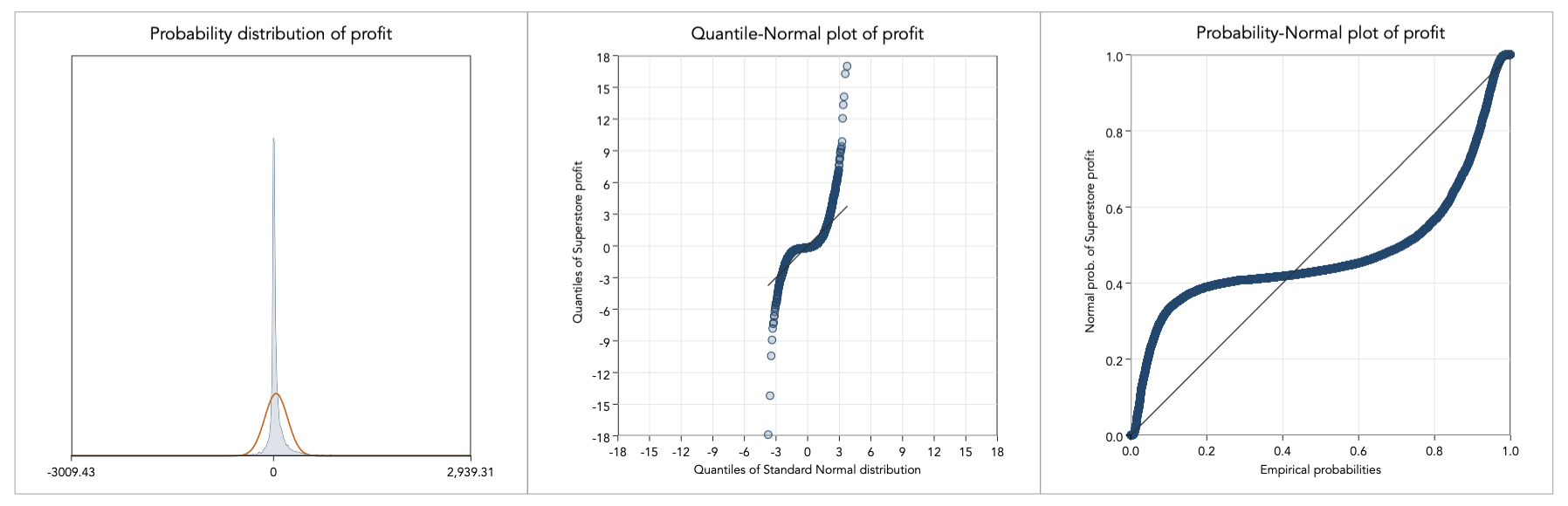
This is an awkward distribution and would be a challenge to transform. There is considerably kurtosis (at about 54.74). By the looks of the probability density plot and the quantile normal plot, I suspect that this is probably due to the fact that the Profit variable contains observation at different scales. Specifically, Profit is a variable that pools all transactions from a fictional superstore where profit is generally large for appliances, copiers and phones, but quite small for stationery and office supplies. To make this point, here is the tabulated frequencies of product subcategory with the mean and standard deviation of profit within for each subcategory (using Stata’s tabulate,summarize command):

Although one could argue that there could be slightly different pricing margins underlining each product, all these are non-differentiable products and so margins proportional to scale should be competitive. That is to say, I do not believe that this is a matter of mixed populations and do not see evidence of such behaviour (i.e. there is no evident multimodality).
Instead, the problem here is of scale and to proceed with analysis we must first remove the scale effect. To do so, I standardise profit, with mean zero and standard deviation one, within each subcategory and graph again the distribution:
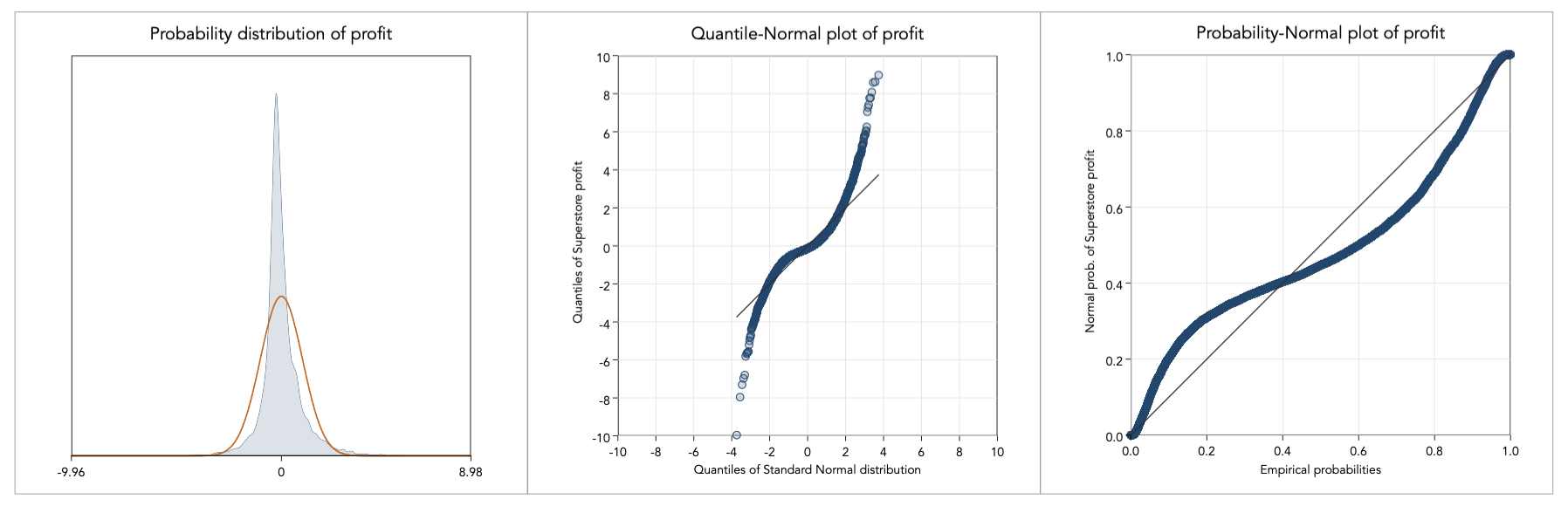
This is certainly a much more manageable distribution to work with. I proceed with trying out the aforementioned transformations: John-Draper, Yeo-Johnson, trigonometric functions, and transforming the source variables:
The distribution of profit is a notoriously difficult distribution to work with but inverse hyperbolic sine seems to work well. This is not surprising. The inverse hyperbolic sine has been studied extensively by Johnson (1949) who demonstrate how it could be used to transform any (–∞,+∞) distribution into normality. The inverse hyperbolic sine is based on the log transformation:
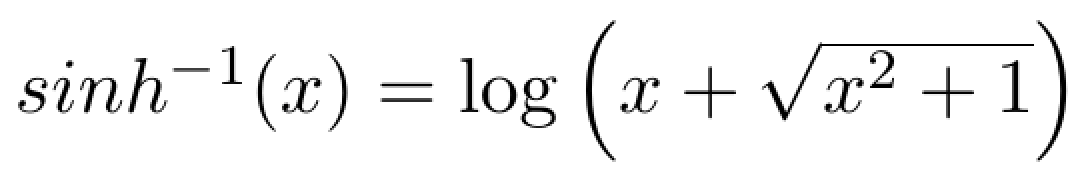
For large values of x the inverse hyperbolic sine behaves like this:
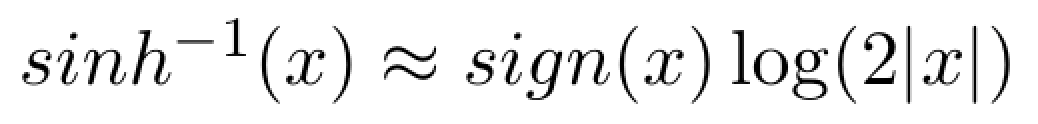
In this case, the inverse hyperbolic sine can be interpreted in exactly the same way as a standard log-transformed variable. In fact, it behaves close to what is also known as the negative-log transformation (Whittaker et al. 2005), defined as follows:
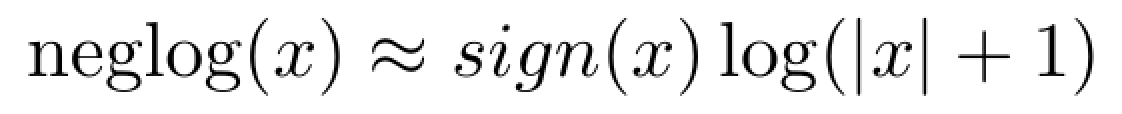
Back to Linearising variables ⟵ ⟶ Continue to [0,1] variables
